
使用llama.cpp加速AquilaChat推理,可在苹果 M1上运行
最后编辑于 2025年2月18日
神经网络的推理代码通常是使用 Python 语言编写的。但是相比于Python,C/C++ 代码运行速度更快,因此一些开发者尝试用 C/C++ 语言实现神经网络,Georgi Gerganov 是其中一位佼佼者,他构建的开源项目 llama.cpp,让开发者在没有 GPU 的条件下也能运行 Meta 的 Llama 模型,甚至在 MacBook 和树莓派上也可以运行 Llama,让没有高级GPU的开发者都能在家动手把玩大模型。
那么,llama.cpp 有何优势呢?
无需任何额外依赖,相比 Python 代码对 PyTorch 等库的要求,C/C++ 直接编译出可执行文件,跳过不同硬件的繁杂准备;支持 Apple Silicon 芯片的 ARM NEON 加速;具有 F16 和 F32 的混合精度;支持 4-bit 量化;
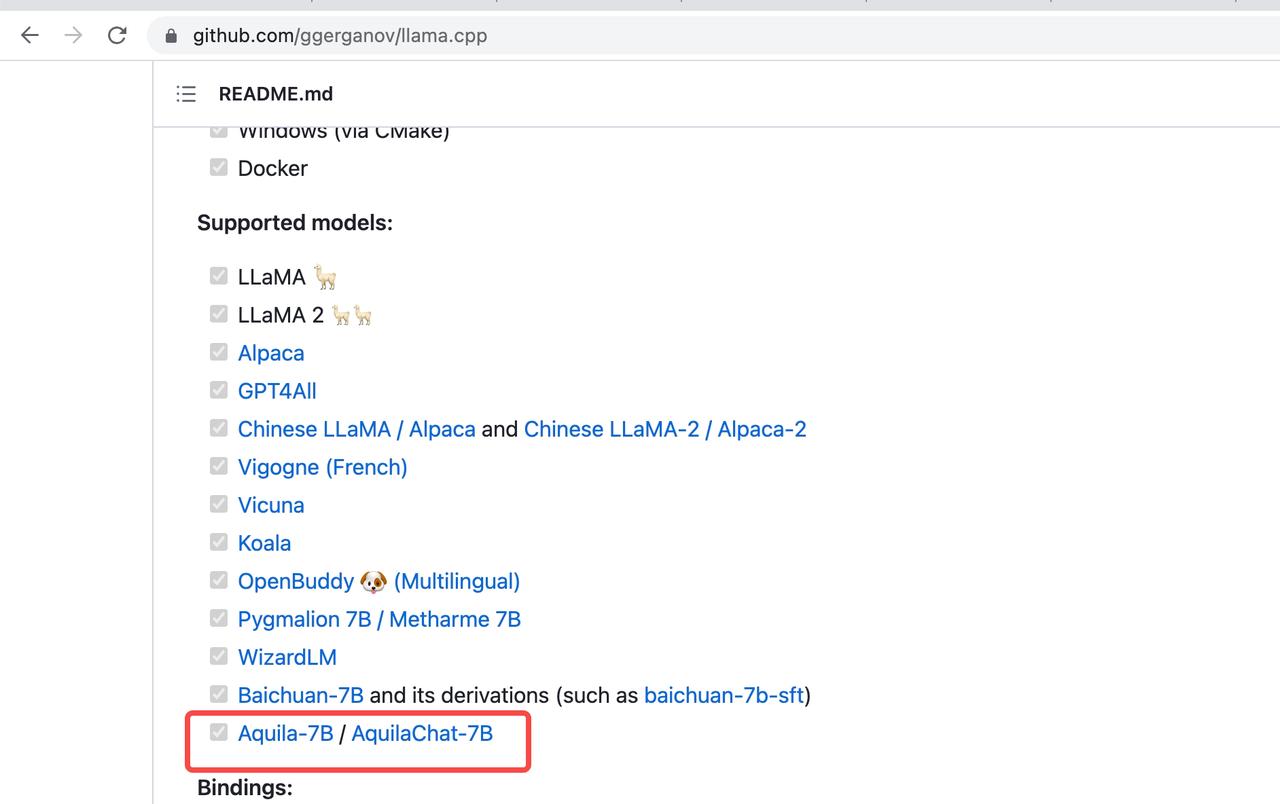
现在,悟道·天鹰Aquila已兼容 llama.cpp。大家可以用llama.cpp享受 Aquila系列模型的极速推理。实测可以在苹果电脑 M1 芯片上跑起来~
值得注意的是,Aquila与Llama结构不同,其tokenizer基于BPE格式,为此我们在llama.cpp增加vocabtype新特性(PR#2487 已被 llama.cpp 官方合并),大家在使用 llama.cpp加速 Aquila推理时,指定bpe即可,无需更多改动。
![]()